Fila de mensagens vs execução durável: o que ninguém te conta antes do SQS quebrar às 3h da manhã
Jonathan Souza · 2026-04-16 · 7 min
TL;DR: Filas de mensagens foram feitas para transportar dados entre serviços, não para orquestrar processos de negócio multi-passo. Quando você usa SQS ou RabbitMQ para coordenar 5 etapas de uma nota fiscal, acaba com 14 filas, 9 consumers e zero visibilidade. Execução durável resolve isso com código linear — sem filas, sem consumers, sem dead-letter queues.
O problema: 14 filas, 9 consumers e uma planilha que ninguém atualiza
Você conhece essa história. Eu vivi ela.
O arquiteto desenhou o sistema certo. Cada serviço publica numa fila de mensagens, o consumer processa, publica na próxima fila, o próximo consumer processa. Retry? Dead-letter queue. Visibilidade? Logs. Ordem? Fila FIFO.
Seis meses depois: 14 filas, 9 consumers, 3 dead-letter queues. E um spreadsheet no Confluence — que ninguém atualiza — explicando qual mensagem vai para onde.
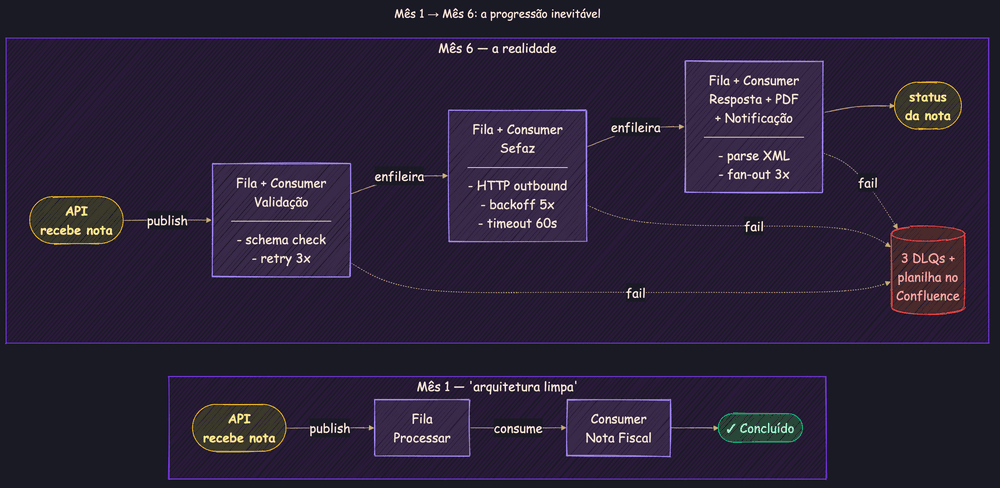
O problema não é a fila. Filas fazem exatamente o que prometem: transportam mensagens do ponto A ao ponto B. O problema é que o time está usando filas para orquestrar processos de negócio. E fila de mensagens não foi feita para orquestração.
Vou usar um exemplo concreto. Uma nota fiscal precisa de 5 passos:
- Validar dados da nota
- Enviar para a Sefaz
- Salvar a resposta
- Gerar o PDF
- Notificar o cliente
Com filas, cada passo vira uma fila e um consumer. Cada consumer precisa de retry próprio, dead-letter queue própria e lógica de compensação própria. O estado do processo vive espalhado entre filas, banco de dados e logs.
O suporte liga: "Onde está a nota 48372?"
Ninguém sabe. Pode estar em qualquer uma das 14 filas. Pode estar na dead-letter. Pode ter sido processada, mas o log não registrou. O dev abre 3 dashboards, faz grep em 4 arquivos de log e, 45 minutos depois, descobre que a mensagem travou na fila 3 porque o consumer crashou e não fez acknowledge.
Isso não é um cenário hipotético. Dados da Inngest, que analisou o comportamento de 50.000 usuários, mostram que 52% dos times batem em falhas de retry já no primeiro dia de operação com filas. A progressão é previsível: começa simples, escala em complexidade, e eventualmente ninguém entende o fluxo inteiro.
Onde a fila de mensagens quebra — e o que ninguém te avisa
Filas são excelentes para o que foram projetadas: desacoplar serviços, absorver picos de carga, distribuir trabalho entre consumers. Se você precisa mover uma mensagem de A para B com garantia de entrega, SQS e RabbitMQ funcionam.
O problema começa quando o processo de negócio tem mais de um passo.
Estado distribuído
Com 5 filas e 5 consumers, o estado de uma execução vive em 5 lugares diferentes. Se o passo 3 falha, como você sabe o que os passos 1 e 2 já fizeram? Precisa consultar o banco, os logs e talvez a própria fila. Isso é o cenário clássico de orquestração sem filas que deveria existir — mas com filas, não existe.
Compensação impossível
Se o envio para Sefaz falha depois que a validação já passou, quem desfaz? Cada consumer é independente. Não existe um coordenador. Você acaba escrevendo lógica de compensação manual — try/catch distribuído entre 5 serviços. Quem já tentou implementar uma saga com filas sabe: o código de compensação acaba maior que o código de negócio.
Visibilidade zero
Qual a diferença entre fila de mensagens e execução durável? A resposta mais prática: na fila, a mensagem some dentro de uma caixa preta e você torce para ela sair do outro lado. Na execução durável, cada passo é visível, auditável e rastreável. Quando o suporte pergunta "onde está a nota 48372?", você tem a resposta em segundos — não em 45 minutos de grep.

O custo invisível
O time de DevOps gasta 20% do tempo gerenciando filas. O time de backend gasta 30% debugando mensagens perdidas. O CTO olha para a conta da AWS e SQS virou o terceiro maior custo. Mas o pior custo é o que ninguém mede: o dev que virou engenheiro de infraestrutura sem perceber. Em vez de escrever regra de negócio, ele escreve retry com backoff, lógica de dead-letter queue, e consumers que tratam duplicatas.
Execução durável: código linear, estado persistido, retry por passo
Execução durável é um conceito simples: o runtime persiste o estado do seu código linha por linha. Se o processo cai no passo 3, ele retoma exatamente do passo 3 — sem reprocessar os passos 1 e 2, sem perder estado, sem consultar filas.
Com skail, os mesmos 5 passos da nota fiscal ficam assim:
[SkailFunction]
public async Task<InvoiceResult> ProcessInvoice(InvoiceRequest invoice)
{
// Valida os dados da nota
var validated = await ctx.RunCommand(new ValidateInvoice(invoice));
// Envia para a Sefaz — retry automático com backoff se falhar
var sefazResponse = await ctx.RunCommand(new SendToSefaz(validated));
// Salva a resposta no banco
var saved = await ctx.RunCommand(new SaveResponse(sefazResponse));
// Gera o PDF da nota
var pdf = await ctx.RunCommand(new GeneratePdf(saved));
// Notifica o cliente
await ctx.RunCommand(new NotifyClient(invoice.ClientId, pdf));
return InvoiceResult.Success(saved.InvoiceId);
}
Sem filas. Sem consumers. Sem dead-letter queues.
Cada [SkailCommand] é durável individualmente. Se o SendToSefaz dá timeout, o skail faz retry automático com backoff — daquele comando específico. Os anteriores já foram persistidos. O ValidateInvoice não roda de novo.
E a compensação? Um try/catch normal:
[SkailFunction]
public async Task<InvoiceResult> ProcessInvoiceWithSaga(InvoiceRequest invoice)
{
var validated = await ctx.RunCommand(new ValidateInvoice(invoice));
try
{
var sefazResponse = await ctx.RunCommand(new SendToSefaz(validated));
var saved = await ctx.RunCommand(new SaveResponse(sefazResponse));
var pdf = await ctx.RunCommand(new GeneratePdf(saved));
await ctx.RunCommand(new NotifyClient(invoice.ClientId, pdf));
return InvoiceResult.Success(saved.InvoiceId);
}
catch (SefazException ex)
{
// Compensação: reverte o que foi feito
await ctx.RunCommand(new RollbackValidation(validated));
return InvoiceResult.Failed(ex.Message);
}
}
Sem framework de saga. Sem DSL especial. O try/catch que você já usa todo dia. O runtime cuida de persistir o estado — você cuida da regra de negócio.
Para processos que precisam esperar sinais externos — como uma aprovação humana ou um callback de webhook — o SkailEvent.WaitForEvent<T>() pausa a execução de forma durável. Sem polling, sem fila de espera, sem timer que consome recursos. O processo "hiberna" e acorda quando o evento chega.
// Espera aprovação por até 72 horas — sem polling, sem fila de espera
var approval = await ctx.WaitForEvent<ApprovalResponse>(
"approval-request",
TimeSpan.FromHours(72)
);
Para fan-out/fan-in — processar vários itens em paralelo e agregar os resultados:
// Processa 100 notas em paralelo — substitui N consumers + fila de agregação
var tasks = invoices.Select(inv =>
ctx.RunCommand(new ProcessSingleInvoice(inv))
);
var results = await SkailTask.WhenAll(tasks);
Isso substitui o pattern clássico de "uma fila de distribuição + N consumers + uma fila de agregação + um consumer de consolidação."
Prova: de 14 filas para uma função
Na Nota Gateway — que processa milhões de transações por mês — o padrão era o mesmo: filas para tudo. Jonathan Souza, que construiu a plataforma, resume: "fila única, tem gargalo." Múltiplas filas resolvem o gargalo, mas criam o problema de orquestração.
Com execução durável, 14 filas viram uma função. 9 consumers desaparecem. O time de DevOps foca em coisas que importam — e a equipe de desenvolvimento depende menos de DevOps para questões de infraestrutura distribuída.
E o debug? Quando algo falha, você abre o Monitor, digita o ID da transação, e vê:
ValidateInvoice ✓ (12ms)
SendToSefaz ✓ (340ms) — retry 1/3
SaveResponse ✓ (28ms)
GeneratePdf ✗ timeout — retry 2/3 em andamento
NotifyClient ⏳ pendente
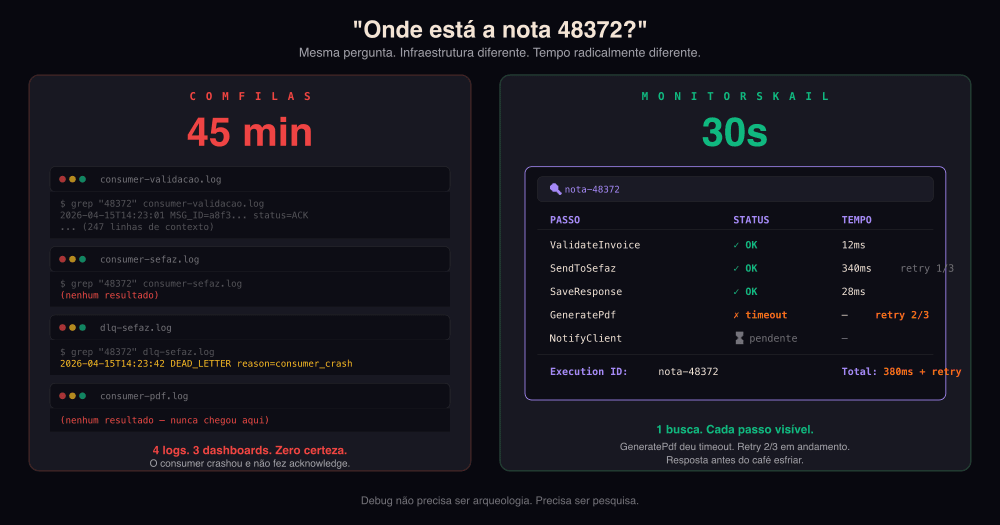
O suporte liga: "Onde está a nota 48372?" Resposta em 30 segundos. Não em 45 minutos.
Os números concretos: a equipe da eNotas, usando a mesma plataforma de execução durável, reduziu o tempo de resolução de bugs complexos de 16h para 2h30 em média. Desenvolvimento ficou 5 a 6 vezes mais rápido do que na infraestrutura anterior. E a equipe passou a depender menos do time de DevOps para questões de infraestrutura distribuída.
Conclusão
Filas são ferramentas excelentes — para transportar mensagens. Mas quando você usa uma fila para orquestrar um processo de negócio de 5 passos, está construindo um sistema distribuído com as peças erradas. O resultado é previsível: complexidade exponencial, visibilidade zero e um time inteiro que gasta energia mantendo infraestrutura em vez de escrever regra de negócio.
Execução durável não é uma abstração nova. É código linear — o mesmo C# que você já escreve — com a garantia de que cada passo é persistido, cada retry é automático e cada execução é rastreável.
Se a sua arquitetura de filas está funcionando e o time dorme tranquilo, não mexa. Mas se você tem mais dead-letter queues do que features no backlog, talvez o problema não seja a fila — talvez seja o que você está pedindo para ela fazer.
-> Comece em 10 minutos em docs.skailhq.com — getting started -> Veja o padrão de Saga com compensação na documentação